神经网络
摘要
神经网络可以说是目前人工智能算法中应用最为广泛的算法之一,相比Linear regression 、logistics regression、decision tree等机器学习算法等会复杂不少,变化也很多。本文从向量矩阵的角度去理解BP神经网络的数学原理,这个过程会显得更加清晰、简洁。我们以最经典的神经网络三层网络二分类模型为例,逐步推导数学公式,三层网络简单说明如下:
- 输入层,不做处理,只是输入数据
- 隐藏层,单元数为 我们就以RELU为激活函数,另外一个常用的是sigmoid,我们把激活函数封装成一个类,可以随时替换
- 输出层为一个单元,由于是二分类,我们就用sigmoid拟合对应类1的概率
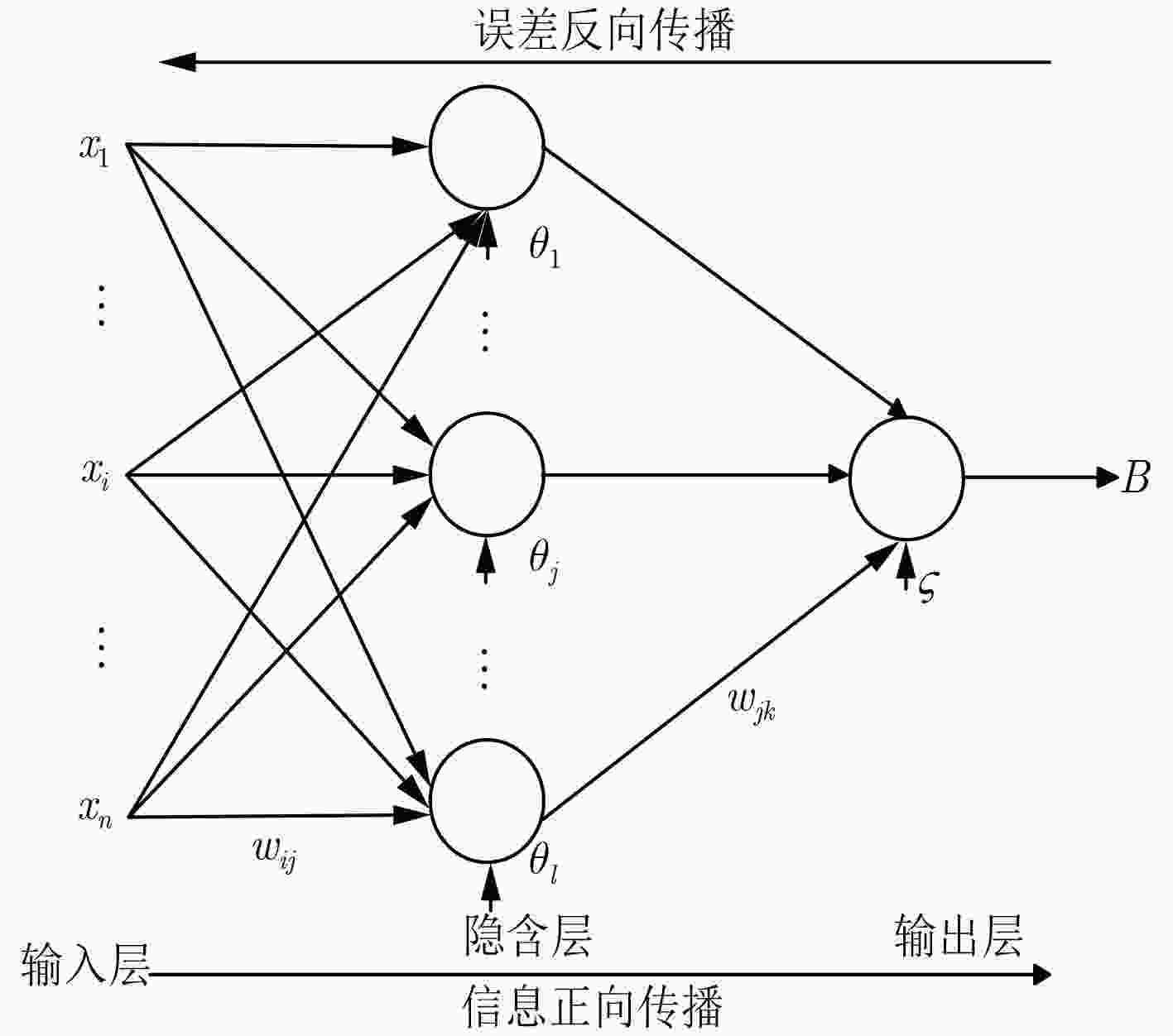
符号定义
- 表示输入样本向量矩阵,表示样本集的期望输出标记(有可能是0/1标记的向量,有可能是onehot的矩阵),本文示例由于是二分类,那么Y的每个元素要么是0要么是1,是m个元素的向量,但是在运算中为了通用将其转换为的矩阵。
- 为样本数量,为样本向量的维度。
- 激活函数用表示,隐藏层激活函数使用RELU函数:,输出层为sigmoid函数,输出为1类的概率
- 隐藏层输出为,输出层的输出为
- 隐藏层单元的参数为, 个隐藏层单元的参数矩阵为,输出层单元的参数为,个输出层单元的参数矩阵为。
- 虽然本文使用二分类即输出单元为1个,但是仍然使用矩阵 和 表示,从而使得算法是通用的,改成onehot+softmax方式的多分类,也是适用的。
- 从输入到输出的公式:
- 注:这里的线性变换并没有使用偏置,通过在增加一个全1的列,达到同样的效果。
forward公式推导
其中(1)式即为信息正向传导的向量化公式相应的python代码实现:
#forwardLh = np.dot(X, Wh)Yh = funcActivation.cal(Lh) #隐藏层输出Yh = np.insert(Yh, np.shape(Yh)[1], values=np.ones(m), axis=1)#add all 1 colLo = np.dot(Yh, Wo)Yo = funcOut.cal(Lo)其中 funcActivation 为隐藏层激活函数的封装,这里使用的Relu,funcOut为输出层激活函数的封装,使用的是sigmoid。
xxxxxxxxxxclass ReLU: def cal(self, z): return np.clip(z, 0, np.inf) def grad(self, x): return (x > 0).astype(int)class Sigmoid: def cal(self, z): return 1 / (1 + np.exp(-z)) def grad(self, x): z = self.cal(x) return z*(1-z)损失函数
最常用的有Mean Square Error均方差损失函数,用于分类的Cross Entropy等。本文以经典的MSE为例。如下(2)式是MSE损失函数的向量化表示。
误差反向传播
我们目的是最小化损失函数,通常使用梯度下降法,逐渐逼近最小极值点。需要逐渐求解参数主要是两个:
和 ,下面分别计算对应损失函数的偏导数。
其中(3)式利用迹 的性质,所以前后两项一样(4)式到(5)式利用了迹的性质,其中表示矩阵各个元素相乘,对应numpy的multiply。神经网络梯度下降求解参数的时候,是从输出层到隐藏层逆着计算的,所以称之为“反向传播”,因此首先求对的偏导,此时相当于常数,故(6)式的 忽略,继续推导:
这里(7)式到(8)式利用了标量对向量或矩阵微分 的性质。对应python实现:
xxxxxxxxxxdelta = np.multiply(self.lossFunc.grad(Yo, Y) , funcOut.grad(Lo))dO = np.dot(Xo.T, delta)
同理继续推导 :
对应的python的实现:
xxxxxxxxxxdelta = np.multiply(self.lossFunc.grad(Yo, Y) , funcOut.grad(Lo))dH = np.dot(X.T, np.multiply(np.dot(delta, Wo.T[:,:-1]) , funcActivation.grad(Lh)))显式使用偏置的数学推导
以上是使用通过 增加全1的列的方式,省略偏置,下面再推导一下使用偏置的方式
其中 跟(8)式的结果相同,继续推导 :
下面推导 和 :
显然 跟(11)式的结果相同,继续推导 :
总结
多层网络
本文实现的是基于输入层、隐藏层、输出层经典的三层神经网络架构,在此基础上可以实现更多隐藏层的神经
网络。我们观察 隐藏层的参数基于损失函数的偏导(11)式与输出层的 (8) 式区别:
我们观察到规律, 可以分成3项, 项是自己这一层的输入,
为上一层的反馈,第3项 为本层激活函数的导数,同理,
也可以看出三项,其中 为损失函数的导数,我们可以把他看成输出层的上一层的反馈值,所以
每层的参数矩阵的偏导可以统一公式为:
linear regression
如果把隐藏层去掉,输出层的激活函数也去掉,那么只有一层的神经网络就是多元线性回归。
Logistics regression
如果把隐藏层去掉,输出层的激活函数使用sigmoid,那么只有一层的神经网络就是就变成了逻辑回归。
关于隐藏层数量的选择
有一些启发式的公式选择隐藏层数量,但是主要还是通过实验选择最恰当的参数,这里可以使用交叉验证的
方式。如将训练样本3/7分割为验证数据集和训练数据集,然后先从少的隐藏层数量开始试,选择在训练
数据集上拟合效果好,同时在验证数据集上同样具有接近准确度的参数作为最终参数结果。
程序实现
使用python库sklearn自带的数据集breast_cancer,共569行数据,30个维度。完整python实现代码:
ximport numpy as np from sklearn import datasetsfrom sklearn.datasets import load_breast_cancerfrom sklearn import preprocessingimport matplotlib.pyplot as pltfrom sklearn.metrics import r2_scoredataset = NoneDT_FLAG = 1 #1测试预测,2测试回归拟合if DT_FLAG: dataset = load_breast_cancer()else: dataset = datasets.load_boston()class ReLU: def __init__(self): return def cal(self, z): return np.clip(z, 0, np.inf) def grad(self, x): return (x > 0).astype(int)class Sigmoid: def __init__(self): return def cal(self, z): return 1 / (1 + np.exp(-z)) def grad(self, x): z = self.cal(x) return z*(1-z)class LossMSE: def __init__(self): return def loss(self, y_pred, y): return np.sum(np.multiply((y_pred - y) , (y_pred - y))) / 2 /int(y.shape[0]) def grad(self, y_pred, y): return (y_pred - y)/y.shape[0]class LossCrossEntropy: def loss(self, y_pred, y): eps = np.finfo(float).eps cross_entropy = -np.sum(y * np.log(y_pred + eps)) return cross_entropy def grad(self, y_pred, y): grad = y_pred - y return gradclass LinearOut:#如果用于回归,只是线性输出,不做任何转换,是的可以有统一的结构 def cal(self, z): return z def grad(self, x): self.gradCache = np.ones(np.shape(x)) return self.gradCacheclass NN: def __init__(self): self.Wh = None #隐藏层参数w self.Wo = None #输出层参数w self.numHideUnit = 5 self.funcActivation = ReLU() #隐藏层激活函数 if DT_FLAG: self.lossFunc = LossMSE() self.funcOut = Sigmoid() else: self.lossFunc = LossMSE() self.funcOut = LinearOut() return def fit(self, X, Y): scalerX = preprocessing.StandardScaler().fit(X)#StandardScaler Y = Y.reshape(-1, 1) X = scalerX.transform(X) if not DT_FLAG: scalerY = preprocessing.StandardScaler().fit(Y)#MinMaxScaler Y = scalerY.transform(Y) m, n = np.shape(X) funcActivation = self.funcActivation funcOut = self.funcOut # 10 1000 0.01 for breat cancer numLayerHide = 5 maxIterTimes = 2000 eta = 0.01 if DT_FLAG: eta = 10 else: #maxIterTimes = 100000 eta = 0.001#eta = 0.00001 pass outputNodeNum = 1 Wh = np.random.rand(n, numLayerHide) * 0.01 Bh = np.random.rand(numLayerHide) * 0.01 Wo = np.random.rand(numLayerHide, outputNodeNum) * 0.01 #Why +1? for reserver b Bo = np.random.rand(outputNodeNum) * 0.01 errLog = [] dO_Old = 0 dH_Old = 0 for i in range(maxIterTimes): #forward Lh = np.dot(X, Wh) + Bh Yh = funcActivation.cal(Lh) #隐藏层输出 Lo = np.dot(Yh, Wo) + Bo Yo = funcOut.cal(Lo) loss = self.lossFunc.loss(Yo, Y) errLog.append(loss) if loss < 0.001: print('fit finish', i) break delta = np.multiply(self.lossFunc.grad(Yo, Y) , funcOut.grad(Lo)) dBo = delta dWo = np.dot(Yh.T, dBo) dBh = np.multiply(np.dot(delta, Wo.T) , funcActivation.grad(Lh)) dWh = np.dot(X.T, dBh) Wo = Wo - eta * dWo Wh = Wh - eta * dWh Bo = Bo - eta * dBo Bh = Bh - eta * dBh score = 0 if DT_FLAG == 0: score = r2_score(Yo, Y) else: score = r2_score((Yo > 0.5).astype(int), Y) print('score', score) return if __name__ == '__main__': nn = NN() print('data', dataset.data.shape) nn.fit(dataset.data, dataset.target)